COUNT
레코드의 전체 개수 구하기 위해 사용
SELECT count(*) FROM employees;
IS NULL, IS NOT NULL
| IS NULL | 컬럼의 데이터가 NULL인 레코드만 출력 |
| IS NOT NULL | 컬럼의 데이터가 NULL이 아닌 레코드만 출력 |
||
속성 결과들의 결합을 하기 위해 사용
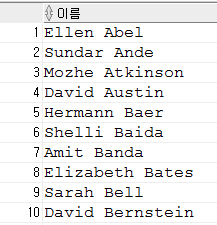
SELECT first_name || ' ' || last_name
FROM employees
;
NVL 함수
데이터가 null일 경우 다른 지정값으로 대체
SELECT employee_id 사원번호,
first_name || ' ' || last_name 사원명,
salary 월급여, commission_pct 커미션지급률,
(salary * 12) + ((salary * 12) * NVL(commission_pct, 0)) 연봉
FROM employees
;commission_pct에 null이 들어가 있을 경우 0으로 대체해서 사용한다.

ORDER BY, ASC, DESC, DISTINCT
| ORDER BY | 검색 결과의 정렬 |
| ASC | 오름차순 정렬(생략 가능) |
| DESC | 내림차순 정렬 |
| DISTINCT | 중복된 내용을 지우고, 출력하기 위해 사용. 대표값만 사용함 |
오라클 내장 함수
1. 숫자형 함수
| ABS | 절대값 | SELECT ABS(-100) FROM DUAL; |
| SEIL | 올림 | SELECT CEIL(10.2) FROM DUAL; |
| FLOOR | 버림 | SELECT FLOOR(-10.2) FROM DUAL; |
| MOD | 나머지 | SELECT MOD(9, 4) FROM DUAL; |
| ROUND | 반올림 | SELECT ROUND(314.1592, 1) FROM DUAL; *양수일 경우 소수점 밑의 자리수, 음수를 넣으면 반대로 소수점 이상의 자리수 |
| TRUNC | 절삭 | SELECT TRUNC(7355.9337, -2) FROM DUAL; |

2. 문자 함수
| CONCAT | 속성끼리 결합, 문자 추가 시에 사용한다. |
* CONCAT과 ||의 공백 사용시의 차이점
| || | SELECT first_name||' '||last_name||' '||JR 이름 FROM employees; |
| || 사이에 작은 따옴표를 사용해서 공백을 쉽게 추가할 수 있다. | |
| CONCAT | SELECT CONCAT(CONCAT(CONCAT(first_name, ' '), last_name), ' JR') FROM employees; |
| 결합을 사용할 때마다 CONCAT 함수를 사용하기 때문에 번거로움이 있다. |
| INITCAP | 문자열의 첫 문자만 대문자로, 첫 문자를 제외하고는 소문자로 변환한다. |
SELECT INITCAP('programmiNG') FROM DUAL;

| LOWER, UPPER | 문자열 전체를 소문자로 또는 대문자로 변환 |
SELECT first_name, LOWER(first_name), UPPER(first_name)
FROM employees;
first_name에서 LOWER를 사용한 부분은 소문자로 출력되고, UPPER를 사용한 부분은 대문자로 출력되었다.
| LENGTH | 문자열 길이출력 |
| SUBSTR | 문자열에서 특정 문자열 추출 |
SELECT first_name || ' ' || last_name,
LENGTH(hire_date) 입사일길이,
SUBSTR(hire_date, 1, 4)|| '년' ||
SUBSTR(hire_date, 6, 2)|| '월' ||
SUBSTR(hire_date, 9, 2)|| '일' 입사일,
hire_date 전체입사일
FROM employees; 
SUBSTR(데이터, 시작 위치, 단어의 갯수)를 의미한다.
즉, 년도는 1번째부터 4개의 단어까지, 월은 6번째부터 2개의 단어, 일은 9번째부터 2개의 단어를 출력한다.
JAVA의 배열은 0부터 시작하지만, DATABASE의 배열은 1부터 시작한다.
| INSTER | 문자열에서 특정 문자/문자열의 위치 출력 |
| 검색하는 컬럼, '문자', 검색을 시작하는 문자의 위치, 순번(n번째로 나와있는 문자의 위치) | |
| 위치값은 맨 앞에서부터 시작. 찾는 위치는 뒤쪽에서부터 지정할 수 있다. |
SELECT INSTR('abc.def.ghi.txt', '.', -1, 1)
FROM DUAL;
-1은 음수이기 때문에 'abc.def.ghi.txt'에서 .을 오른쪽에서 첫번째로 위치되어 있는 것을 찾는다.
즉, 3번째 위치하고 있는 . 을 찾는 것이기 때문에 결과는 왼쪽부터 카운트하여 12가 나온다.
3. 날짜 함수
| SYSDATE | 시스템의 현재 날짜 정보 출력 |
SELECT SYSDATE, -- 현재 시간
SYSDATE - 1 하루전, -- 현재 시간에서 하루전
SYSDATE - 1/24 한시간전, -- 현재 시간에서 한시간전
SYSDATE - 1/24/60 일분전, -- 현재 시간에서 1분전
SYSDATE - 1/24/60/60 일초전 -- 현재 시간에서 1초전
FROM DUAL; 
| SYSTIMESTAMP | 현재 일자/시간 출력(시스템) |
| 최소단위 = 10억분의 1초(주로 컴퓨터에서 쓰기 때문에 거의 쓸일이 없음) |
SELECT SYSTIMESTAMP FROM DUAL;
| ADD_MONTHS (달수 추가) |
-2일 경우 2달 전. |
SELECT ADD_MONTHS(SYSDATE, -2) FROM DUAL;
| MONTHS_BETWEEN (달1, 달2) |
달1과 달2 사이의 달의 수 계산 |
| ex. 프로젝트 기간 확인할 때 사용 |
SELECT MONTHS_BETWEEN(TO_DATE('2020-08-05', 'YYYY-MM-DD')
,TO_DATE('2019-02-05', 'YYYY-MM-DD')) 차이달
FROM DUAL;
| LAST_DAY | 달의 마지막 날짜 구하기 |
SELECT SYSDATE, LAST_DAY(SYSDATE)
FROM DUAL;
| NEXT_DAY(d, c) | d : 날짜, c : 요일 = 1(일) ~ 7(토) |
SELECT NEXT_DAY(SYSDATE, 5) "다음주 수요일"
FROM DUAL;

4. 형변환 함수
NUMBER >> CHAR : TO_CHAR
SELECT 12345678 - 1, TO_CHAR(12345678)- 1 FROM DUAL;
형변환 산술연산이 가능함
SELECT 12345678 || '' FROM DUAL;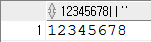
NUMBER 뒤에 ' '을 붙이면 문자형으로 변환이 가능함.
SELECT TO_CHAR(12345678, '999,999,999') FROM DUAL;
금액형식으로 출력하는 형식으로 만들 수 있음.
SELECT TO_CHAR(12345678, '999,999') FROM DUAL;입력 숫자에 비해 자리수를 적게 잡아둔다면 오류 발생함
SELECT TO_CHAR(16, '0009') FROM DUAL;
| 9 | 실제로 숫자가 출력되는 부분 |
| 0 | 여백공간 |
CHAR >> NUMBER : TO_NUMBER
SELECT TO_NUMBER('012345') FROM DUAL;
숫자이기 때문에 0을 출력 안 함
SELECT TO_NUMBER('012345A') FROM DUAL;문자가 들어가면 오류가 발생함
DATE >> CHAR : TO_CHAR
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD'),
TO_CHAR(SYSDATE, 'YYMMDD'),
TO_CHAR(SYSDATE, 'YYYY') 연도,
TO_CHAR(SYSDATE, 'MM') 월
FROM DUAL;
원하는 위치의 데이터만 뽑아올 수 있음.
원래의 SYSDATE 출력 형식에는 /가 들어가 있는데 다른 유형으로 출력 가능함.
CHAR >> DATE : TO_DATE
SELECT TO_DATE('20200101132510', 'YYMMDDHH24MISS') FROM DUAL;
GROUP BY & HAVING
원하는 데이터를 컬럼별로 합하여 출력
집계함수
중간 데이터가 많지만 최종적인 결과는 그룹에 대한 하나만 나옴.
| SUM | 총합 |
| AVG | 평균 |
| COUNT | 레코드 개수 |
| MAX | 최대값 |
| MIN | 최소값 |
WHERE과 HAVING의 차이점)
SELECT department_id, SUM(salary*12),COUNT(employee_id)
FROM employees
WHERE department_id >= 50
GROUP BY department_id;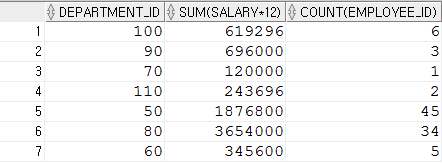
SELECT department_id, SUM(salary*12),COUNT(employee_id),
MAX(salary * 12), MIN(salary * 12)
FROM employees
GROUP BY department_id
HAVING department_id >= 50;
| WHERE | 해당되는 조건에 맞지않는 결과를 제외하고 처리함 >> 처리 횟수 1번 |
| HAVING | 결과를 처리한 후, 해당되는 조건에 맞지않는 결과를 삭제 >> 처리 횟수 2번 |
'SQL' 카테고리의 다른 글
| 0427 SQL - 시퀀스, 트랜젝션 (0) | 2020.04.28 |
|---|---|
| 0424 SQL - JOIN (0) | 2020.04.27 |
| 0420 SQL - ALTER(테이블 관리), DML (0) | 2020.04.21 |
| 0416 SQL - 테이블 생성, 제약조건 (0) | 2020.04.17 |